Table of contents
Machine Learning Monitoring Overview
Machine learning monitoring is a crucial aspect that allows you to develop insights into your ML models in production and ensure that they’re performing as intended. AI monitoring is also a necessary precondition to extracting meaningful business value from your models. Without understanding how your model’s predictions are impacting downstream business KPIs and revenue, it’s impossible to make further improvements and optimizations to your modeling pipeline. AI monitoring ensures that you are able to take preemptive actions before small modeling problems turn into catastrophic, system-level failures.
As an example, consider a fraud detection model implemented by a bank or other financial institution. Say the model is deployed into the production environment and begins to run on every customer-posted transaction. Without proper monitoring tooling in place, it might be difficult to assess the reality of how the model is performing. For example, business executives might initially be satisfied with the model’s performance based on a significant decrease in fraudulent transactions being reported by customers. There’s just one problem—the model makes a high number of false positive predictions, resulting in good faith, long term customers being locked out of their accounts and prevented from using their credit cards. Rather than go through the lengthy and cumbersome process of calling customer support and having these erroneous blocks reversed, the affected customers simply take their banking elsewhere. This customer loss is unknown to business executives until 3 months later when it is reflected in the quarterly earnings report. At this point, stanching the outflow of customers is a prolonged process of damage control, one that could’ve been prevented much earlier if proper monitoring infrastructure had been in place.
Why Do You Need ML Model Monitoring?
The previous example illustrates the importance of proactively identifying modeling weaknesses before they propagate into major issues. ML model monitoring systems are designed to do just that, by providing visibility into how models are performing in production and enabling teams to address weaknesses before issues escalate. This stands in stark contrast with the backward-looking approach taken by many teams, in which dashboarding and troubleshooting are only conducted in response to customer complaints. While these may help to unroot some (but not all) modeling problems, it is often too late, as the business impact of the modeling miscalibration has already occurred. Proactive resolution before negative downstream effects emerge is key to building a business which prospers, rather than falters, in response to AI-driven growth.
Monitoring gives complete visibility into AI-driven applications, from the start point of data ingestion, to the issuing of a prediction, to the endpoint of an affected business KPI. This allows data scientists and engineers to identify critical issues such as data and concept drift, problems that can’t be solved through simple methods such as model retraining alone. Furthermore, ML model monitoring yields granular insights that can be used to optimize model performance and enables organizations to take a product-oriented, rather than research-oriented, approach to their modeling workflow.
Getting Started with AI Monitoring
To get started with AI monitoring is easier than you might think. The first step is to define useful performance metrics that will guide your model development. These metrics should align with the business value that you hope to achieve from your ML model. They should also be closely monitored at a granular level, meaning that a model’s performance based on the metric should be tracked relative to different segments of the data, because you never know where an issue is going to arise. Effective metrics are easy to understand and compute while capturing the correct business behavior that is expected based on a model’s predictions. For instance, in an ad recommendation system, a relevant metric would be a function comparing the different possible business results (such as ignore, click, conversion after click and perhaps even conversion size) to the confidence level the model had in choosing the specific ad. On the other hand, for a fraud detection model, a simpler metric would suffice, such as a mean squared error loss comparing how wrong your model was with its fraud confidence relative to an actual ground truth.
A somewhat nuanced aspect of monitoring is that it’s important to track both feature and output behavior. Feature behavior refers to the way in which features shift and transform over time. Features are crucial inputs for ML models, and tracking their behavior can help to better understand and explain the behavior and output of the model. In fact, there are many open-source tools such as SHAP and LIME which can take input features and use them to explain the outputs of any ML model. Additionally, it’s a good practice to collect metadata on your users in order to be able to segment in response to anomalous metrics. For example, when your monitoring solution identifies that data drift has occurred, having access to metadata will allow you to define user segments and pinpoint the ones which are causing the model to need retraining.
This leads us to the golden rule of AI monitoring—track everything! It’s crucial to track all data as it flows through the entire ML pipeline, from ingestion to preprocessing to training, test, and inference time. Having full visibility into the data moving through your system allows you to more easily debug issues as they arise.
How to Track ML Model Performance
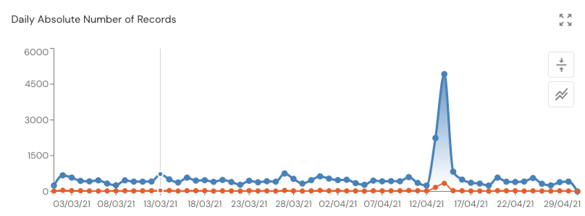
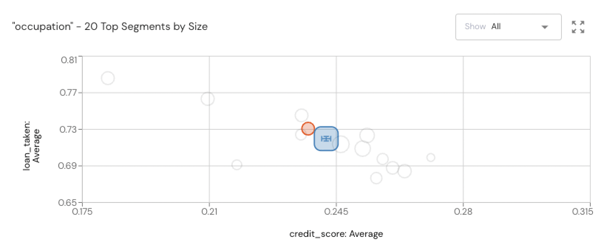
The best ML monitoring tools provide automatic anomaly detection at a high level of granularity. This is important because ML models are often quite sensitive to changes in their inputs, so spurious predictions and anomalous behaviors are often due to small distributional shifts. In fact, these types of shifts, in both a model’s inputs and the relationships between input and target variables, are given their own names: data and concept drift. Monitoring for these two types of model drift involves looking at small, granular segments of data first as changes to these often foreshadow larger distributional shifts. It’s also vital to define metrics that allow you to correlate increased model performance to improvement on business KPIs so that optimizing these metrics leads to better business results.
A good monitoring system will also have features dedicated towards tracking specific types of anomalies, such as those arising in time series, metrics exceeding (or falling below) predetermined threshold values, model outliers, and nuanced, difficult to detect biases.
The following graphic details the types of anomalies you can expect to see. Outliers are a common issue that can throw off susceptible metrics such as average values and can lead to erroneous business decisions. A continuous decrease in model performance after offloading into production, deemed model decay and often attributable to data and concept drift, is problematic for obvious reasons. A model which is no longer adequately representing the underlying data distribution must be detected and likely retrained. Finally, time-series measurements are often sensitive to noise and must be monitored closely to ensure that the models which ingest this data are not overfitting or picking up on erroneous patterns.
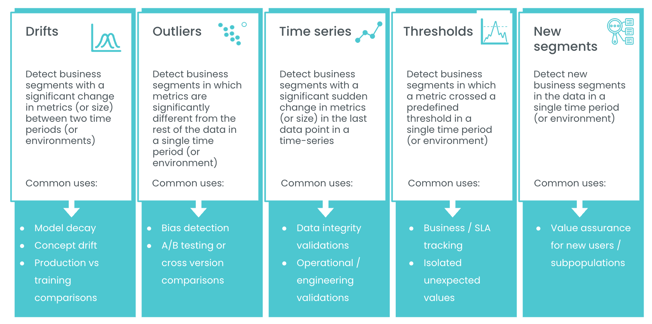
Since ML models vary widely in their behavior and handle many different types of data, having access to a well-stocked monitoring toolkit providing a variety of features is essential for ensuring that total process visibility is enabled in every possible scenario.
Largest Challenges in AI Monitoring and How to Overcome Them
Perhaps the biggest challenge faced by businesses looking to utilize AI solutions is getting stuck in the research mindset. This is natural as AI originally took root as a research discipline, and most of the advancements in the field arise out of academia or industry research labs. That said, staying in the research mindset can forestall effective action and the proper use of AI in a business setting. The better thing to do is to take a product oriented approach where AI is viewed as a seamless integration into the business process and is evaluated based on its effects on concrete business measurements such as KPIs. In this setting, collecting continuous feedback on your models’ performance is key to developing a working AI system that achieves the desired business outcomes. This might mean setting up proxy feedback, such as human evaluations or confidence scores, for long-running processes where direct feedback from the system itself might not be immediately possible. It may very well also mean integrating monitoring into disparate systems that only occasionally interact, as sometimes the feedback that you need access to is siloed within a different platform or team. For example, imagine you’ve built an ML-powered chatbot that fields customer support requests. You’ll certainly need logs of customer interactions with this system in order to understand what percentage of requests are being properly redirected as well as to assess how helpful the bot is in preemptively resolving simple issues by linking out to FAQs and other product documentation. Ideally, getting these logs would be easy, but unfortunately in real-world organizations, data is often haphazardly stored and inaccessible to those who need it most. Effective monitoring often requires that inchoate data storage infrastructure and processes be revamped.
In tandem with addressing data and organizational silos, it can be helpful to take a close look at the rest of your organization’s ML tooling in order to ensure that best practices are being enforced. Chief among these is version control. Just as with software development, ML models and their associated training datasets need to be periodically versioned as changes to both are made. Version control is critical to facilitating rollbacks when unintentional, breaking changes are introduced and for being able to view diffs between versions. Version control also enables simplified A/B testing, where two different versions of a model can be deployed to different subsets of the customer base and preferentially evaluated. With the trifecta of monitoring, A/B testing, and versioning in place, businesses can rapidly iterate on ML models and datasets in order to achieve the best business results without worrying about irreversibly breaking systems and processes.

Finally, as we’ve stressed in the previous sections of this guide, effective monitoring requires digging into data and model performance at a granular level. However, this is not as simple as it sounds. There is a very fine balance to strike so as to monitor at a sufficient level of granularity without paying too close attention to random noise. Proper monitoring tools attenuate their attention such that they automatically identify anomalous data segments without becoming distracted by meaningless variance.
Evaluating AI Monitoring Solutions
Wading through all the information online to find the right AI monitoring solution for your business can prove daunting, especially because there’s no standardized checklist to use when evaluating prospective solutions. However, we believe that the best ML monitoring products will offer all of the features discussed so far, such as being business process oriented, allowing you to define custom performance metrics, being able to automatically identify anomalies at a granular level, having the ability to track feature and output behavior, and being able to handle many different types of data from time series to categorical to tabular. It’s also important to verify that any solution you’re considering offers these three must-haves.

There are also solutions that you should specifically shy away from. First off, avoid monitoring solutions that promise to work straight out of the box. Because every ML use case is different, you should expect to have to do some work in defining your unique performance metrics and KPIs, integrating the monitoring tool into your business processes, and configuring common building blocks such as anomaly detection. You should also look to go beyond the plug-and-play monitoring solutions offered by cloud providers. While these provide basic functionality such as model input/output logging and basic data drift detection, they do not offer the contextual data needed to achieve total process visibility and insight into your entire AI system. You should also avoid simplistic tools that only handle a subset of the monitoring process, such as APM tools, anomaly detection tools, experiment tracking tools, and troubleshooting tools. Ultimately, you should only consider fully-featured monitoring platforms that provide all the building blocks you need to observe your entire AI system and business process as well as enable total configurability and granular observability via a broad and customizable feature set.

Finally, you’ll have to address the age-old question of whether you should build your own monitoring platform or buy one that’s commercially available. While building can be the right choice for businesses with vast resources, dedicated engineering staff, and plenty of time to experiment and fine-tune their custom solution, for most organizations buying is the best choice. By buying you get to leverage the expertise, trial and error, and years of dedicated engineering poured into developing the existing solution which will ultimately save you time, money, and headaches in the long run.
Ultimately, we hope this walkthrough can serve as a guide as you look to integrate AI monitoring into your business processes. It represents the many lessons we have internalized while working with countless businesses on establishing best practices around monitoring of their AI systems. While there is no one-size-fits-all solution to ML monitoring, the best platforms will enable you to ensure that you are extracting the maximum value from AI while identifying critical errors before they propagate into real financial impacts. With proper monitoring in place, deploying ML systems should become a relatively quick and painless process that advances your business interests and brings true, long-term value to your organization.