Just recently we published an important update on our growth, from recent customers to our team growth. Today, I’d like to go a little deeper on our current product and share how we’ve been expanding it in multiple areas to create value for our customers.
Our mission
Before diving into the features, let me remind you that our mission is to deliver the most flexible, intelligent, and scalable monitoring platform for production AI / ML environments. In simple terms, it means making it easy to define and ingest data for every ML use case, making it insightful and actionable to track anomalies and making your ML monitoring deployment scalable and reliable. We believe that this is the key to reducing manual labor and to preempting negative business impact for our customers. And without further ado, let’s get deeper into the product.
Data collection and aggregation
AI systems nowadays can be distributed across many machines, they may consist of several phases throughout the model lifecycle, and they may be used by many different systems or business stakeholders. This means that for many companies, collecting and structuring data for ML model monitoring can be pretty challenging.
With Mona, customers can collect and aggregate data from all parts of their AI environment including their training pipelines, inference serving environments, human labeling systems and anywhere else. Customers can import data into Mona using our dedicated open source python SDK, using a REST endpoint, or directly from their data lake/warehouse. Both batch or real-time processing use-cases are supported.
Moreover, data can be imported from multiple sources asynchronously, thus allowing you to continuously update data about a specific inference as more information is received. Some examples are human labeling and a business result which correlates with your model’s prediction, such as whether a loan approved by your AI system was eventually paid in full.
Data abstraction, transformation, and segmentation features
While working with many teams in AI native companies, we found that every AI use case is special: perhaps much of the underlying technology and concepts is similar, but the data, the ML models and the desired business outcomes are unique. Therefore, we need to empower our users to define their AI monitoring schema and datasets in a way that fits their specific use cases.
To meet this need, Mona includes a powerful schema configuration language for defining how data is abstracted, segmented, and then tracked by Mona. For example, customers can choose or define their specific loss functions, numerical ranges for data bucketing, and any other performance metrics to include in the automatic anomaly detection search. This flexibility enables our customers to track sophisticated combinations of business and technical indicators. For example, you could define a metric tracking the relation between the score your model gave to a specific search result and the search result’s respective click-through rate (CTR), effectively measuring how well your model is performing for your business.
AI investigation capabilities
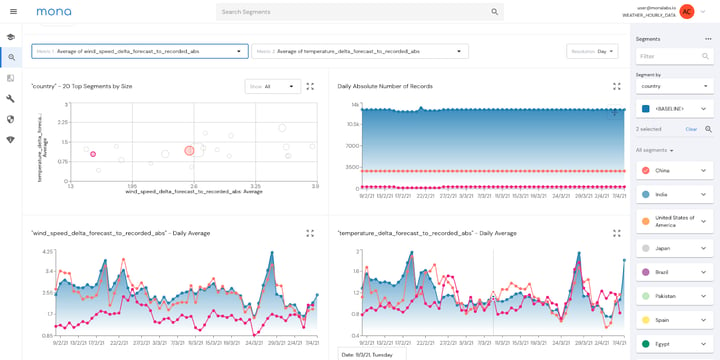
The most fundamental need for data scientists and engineers is to observe and explore their data throughout the entire ML lifecycle, from training data to inference outputs and business metrics. Without an easy way to explore data and correlate between different parts of it, data scientists may spend many hours manually running their own queries on various logs in an attempt to figure out what causes an issue.
For this reason, an early focus of our work at Mona was smart Root Cause Analysis (RCA) and investigation capabilities. Users can leverage the dashboard visualization for exploring and investigating trends in data and ML model behavior, as well as receive critical alerts based on a high signal-to-noise ratio. Our unique noise reduction engine and root cause analysis features enable quick issue resolution, often before any potential impact to the business.
Actionable insights, alerting, and automation
One frequent input from our customers is that for insights to be valuable they have to be actionable, leading to an immediate and focused investigation by the data science team, followed by some immediate action.For this reason, we focused on automating our intelligence layer to bubble up such actionable insights, and we purposefully built alerting and automation as an integral part of our platform. Users can view auto-generated insights about anomalous behavior within specific segments of data regarding drifts, biases, sudden changes, outlier segments and rule-based validations. Insights can also be used more broadly for model performance evaluation such as for A/B testing new model versions.
While the insights are generated automatically, Mona provides the user with complete control for setting the appropriate thresholds and time periods, ad-hoc data filtering for specific insights and a choice from a catalog of over a dozen different proprietary anomaly detection mechanisms.
Based on these insights, users can leverage multi-channel alerting (e.g. via email, Slack, Microsoft Teams, Pagerduty) and also set up automated downstream workflow triggers (e.g. ML model retraining) via webhooks.

What's next at Mona
We are continuing to expand our product and improve on our vision of a full-scale AI observability solution. The vast and growing variability in AI use cases, both on the business side and the technology side, dictates that Mona will not only be flexible, but also comprehensive. To that end, we’re continuously adding new features while extending existing ones.
If you're interested in learning about how our flexible AI monitoring solution can benefit your business, contact us to find out more information.