Monitoring is often billed by SaaS companies as a general solution that can be commoditized and distributed en-masse to any end user. At Mona, our experience has been far different. Working with AI and ML customers across a variety of industries, and with all different types of data, we have come to understand that specificity is at the core of competent monitoring. Business leaders inherently understand this. One of the most common concerns we find voiced by potential customers is that there’s no way a general monitoring platform will work for their specific use-case. This is what often spurs organizations to attempt to build monitoring solutions on their own; an undertaking they usually later regret. Yet, their concerns are valid, as monitoring is quite sensitive to the intricacies of specific use cases. True monitoring goes far beyond generic concepts such as “drift detection,” and the real challenge lies in developing a monitoring plan that fits an organization’s specific use cases, environment, and goals. Here are just a few of our experiences in bringing monitoring down to the level of the highly specific for our customers.
Dueling monitoring objectives
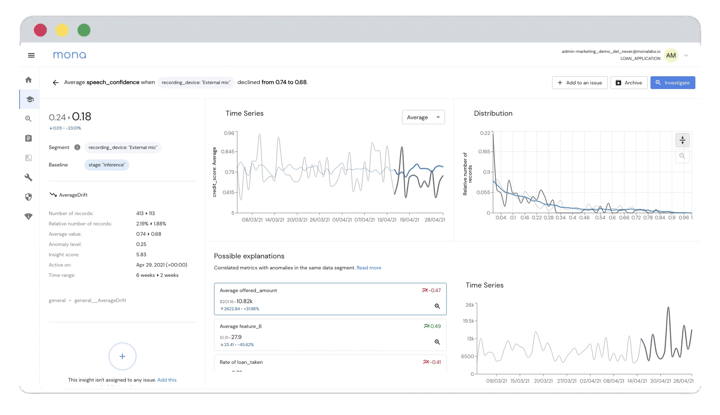
One of our customers is using machine learning for audio analysis. They have both a language detection model and a music detection model running on audio files, and everything is monitored using Mona. One issue they’ve been working to address is that their music and language detection models aren’t performing well for very short calls. However, while they’d like their music detection models to improve for this use-case, they actually expect the language detection model to underperform in this scenario. Achieving this dual objective necessitates a very specific monitoring profile. They only want to receive alerts with respect to underperformance of the music detection model on the short audio files. Furthermore, when calculating metrics like average confidence for the language detection model, they want to be sure to ignore the data associated with the short audio files as it will skew the results. This is a hard requirement, and it isn’t something where they can just skirt the issue by calculating the confidence across all audio clips. They need a way to convey this objective to the monitoring platform, something that’s possible within Mona but not within many other platforms. This sort of very specific requirement varies between use cases but always exists. Most monitoring solutions fail to enable this level of granularity, which leaves them able to only perform basic monitoring tasks, or worse, corrupts the data that is surfaced by the monitoring platform.
Outliers, and whether to care about them
Outliers are another common issue in monitoring. Many monitoring techniques use averages to detect changes in behavior, but outliers can significantly skew these distributions in an unfavorable manner. Outliers are quite common when measuring durations, for example, when assessing latencies. Most latencies will be quite short, but occasionally values will spike due to network issues, system downtime, and other related causes. These infrequent, but extremely high, latencies will skew your averages such that the graphs of this metric will appear quite alarming. However, in many cases, these rare discrepancies are not that urgent, so you’ll want a way to tell the monitoring system to disregard values at the 99th percentile. Of course, this strategy might only apply to some metrics and not to others. Again, a very fine-grained degree of control is necessary to tune the monitoring system to your liking.

Diverse benchmarks
Monitoring is only useful with respect to some benchmark. For example, you might be measuring a certain metric and want to be notified when its value exceeds a certain threshold. Benchmarks vary across organizations and even across use-cases within an organization. Each use-case of every one of our customers differs in things like retrain cadence, data labeling policies, model deployment checklists and tests, delegation of responsibilities for the production environment and models, and many other aspects relating to the productionization of AI. Given these differences, it’s no surprise that teams differ in the benchmarks that they use. Some want to compare inference data behavior to training behavior within the same batch, some want to run the same comparison but with respect to a given model version, others want to examine inference behavior over time, and so on. There are, quite literally, unlimited possibilities for what you might choose to measure and the benchmarks you care about. Generic monitoring solutions miss this point and prescribe a set of fixed tools that are likely not best-suited to your specific use-case. There are very few monitoring solutions that actually provide true freedom and extensibility in terms of how you can direct the tool and delineate your own monitoring requirements.

Summary
Thus when comparing and evaluating different monitoring solutions, be sure to dig into the details. Specific use-cases bring many intricacies, hidden nuances that are not easily grasped upon first glance. Monitoring cannot be performed without taking these nuances into account. While many platforms will offer a generic checklist indicating that they offer drift and bias detection, as well as tools for fairness and explainability, it’s important to understand that the devil is in the details. Just because a specific feature is offered, doesn’t mean it can be tailored to your specific use-case. The real value in a monitoring solution lies in its flexibility, to the granularity at which behaviors can be dissected and metrics can be defined. Mona was built with specificity in mind, as is attested to by the fact that it has been applied across a wide diversity of industries and use-cases. Whatever platform you decide to use, be certain that it can be tailored to grapple with the nuances of the challenges that your product is uniquely facing. Learn how Mona can be tailored for your specific use-case by booking a demo today!